COLUMN report_date_col NEW_VALUE report_date
col report_date_col noprint
SELECT TO_CHAR ( SYSDATE ,'DD-Mon-YYYY:HH:MI') AS report_date_col FROM dual;
TTitle left "*** Rollback Information ( Date: &report_date ) ***" skip 2
Saturday, July 28, 2012
Friday, July 27, 2012
script to identify inefficient sql
This script reports on the apparent efficiency of SQL statements whose information presently
resides in the shared pool
SELECT hash_value stmtid,
SUM (disk_reads) disk_reads,
SUM (buffer_gets) buffer_gets,
SUM (rows_processed) rows_processed,
SUM (buffer_gets) / GREATEST (SUM (rows_processed), 1) rpr,
SUM (executions) executions,
SUM (buffer_gets) / GREATEST (SUM (executions), 1) rpe,
SQL_TEXT
FROM v$sql
WHERE command_type IN (2, 3, 6, 7)
GROUP BY hash_value, SQL_TEXT
ORDER BY 5 DESC
resides in the shared pool
SELECT hash_value stmtid,
SUM (disk_reads) disk_reads,
SUM (buffer_gets) buffer_gets,
SUM (rows_processed) rows_processed,
SUM (buffer_gets) / GREATEST (SUM (rows_processed), 1) rpr,
SUM (executions) executions,
SUM (buffer_gets) / GREATEST (SUM (executions), 1) rpe,
SQL_TEXT
FROM v$sql
WHERE command_type IN (2, 3, 6, 7)
GROUP BY hash_value, SQL_TEXT
ORDER BY 5 DESC
How to interpretate wait events to troubleshoot production problems
- Wait events touch all areas of Oracle—from I/O to latches to parallelism to network traffic
- Wait event data can be remarkably detailed. “Waited 0.05 seconds to read 15 blocks from file 15 starting at block 25008.”
- Analyzing wait event data will yield a path toward a solution for almost any problem
- The wait event interface gives you access to a detailed accounting of how Oracle processes spend their time.
- Wait events touch all aspects of the Oracle database server.
- The wait event interface will not always give you the answer to every performance problem, but it will just about always give you insights that guide you down the proper path to problem resolution.
Thursday, July 26, 2012
Oracle most useful performance fixed view
- V$SQL
- V$SESS_IO
- V$SYSSTAT
The denormalized structure of V$SYSSTAT makes it easy to find out what the system has done since the most recent instance startup, without having to do a join.
- V$SESSTAT
- V$SYSTEM_EVENT
- V$SESSION_EVENT
provides the ability to collect properly session-scoped diagnostic data for Oracle kernel code paths
- V$SESSION_WAIT
Oracle Script to get all objects in a datafile
SELECT DISTINCT segment_name, segment_type,bytes/1024/1024 as "Size (MB)"
FROM dba_extents
WHERE file_id = (SELECT file_id
FROM dba_data_files
WHERE FILE_name = '&datafile')
order by segment_type
FROM dba_extents
WHERE file_id = (SELECT file_id
FROM dba_data_files
WHERE FILE_name = '&datafile')
order by segment_type
Wednesday, July 25, 2012
Most useful grep Options
-h: suppress file names in output
-w: restrict search to whole words only
-c: displays count of matching lines in each file, not the lines themselves
(note this is not the same as $ grep index *.rb | wc -l)
-i: ignore case
-l: list only file names containing matching lines
-n: precede each line with the line number where it was found
-v: display all lines NOT matching pattern
-C: Display NUM lines of context either side of matches
-B: Display NUM lines of context Before the matches
-A: Display NUM lines of context After the matches
-e pattern:
Search for a pattern. Can use multiple times on a line
-r: Search recursively from the current or specificed directory
--include=pattern:
Only search in file names matching pattern
--exclude=pattern:
Do not search in file names matching pattern
Most useful awk programs
awk '{ if (NF > max) max = NF }
END { print max }'
This program prints the maximum number of fields on any input line.
awk 'length($0) > 80'
This program prints every line longer than 80 characters. The sole rule has
a relational expression as its pattern, and has no action (so the default
action, printing the record, is used).
awk 'NF > 0'
This program prints every line that has at least one field. This is an easy
way to delete blank lines from a file (or rather, to create a new file
similar to the old file but from which the blank lines have been deleted).
awk '{ if (NF > 0) print }'
This program also prints every line that has at least one field. Here we
allow the rule to match every line, then decide in the action whether to
print.
awk 'BEGIN { for (i = 1; i <= 7; i++)
print int(101 * rand()) }'
This program prints 7 random numbers from 0 to 100, inclusive.
ls -l files | awk '{ x += $4 } ; END { print "total bytes: " x }'
This program prints the total number of bytes used by files.
expand file | awk '{ if (x < length()) x = length() }
END { print "maximum line length is " x }'
This program prints the maximum line length of file. The input is piped
through the expand program to change tabs into spaces, so the widths
compared are actually the right-margin columns.
awk 'BEGIN { FS = ":" }
{ print $1 | "sort" }' /etc/passwd
This program prints a sorted list of the login names of all users.
awk '{ nlines++ }
END { print nlines }'
This programs counts lines in a file.
awk 'END { print NR }'
This program also counts lines in a file, but lets awk do the work.
awk '{ print NR, $0 }'
This program adds line numbers to all its input files, similar to `cat -n'.
awk -F "\"*,\"*" '{print $3}' file.csv
CSV parsing, prints 3rd field
This can helps you remember the unix cron syntax
# * * * * * command to be executed
# - - - - -
# | | | | |
# | | | | +- - - - day of week (0 - 6) (Sunday=0)
# | | | +- - - - - month (1 - 12)
# | | +- - - - - - day of month (1 - 31)
# | +- - - - - - - hour (0 - 23)
# +- - - - - - - - minute (0 - 59)Tuesday, July 24, 2012
Common Wait Events in Oracle
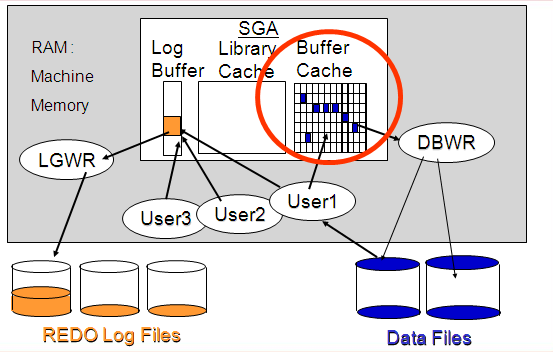
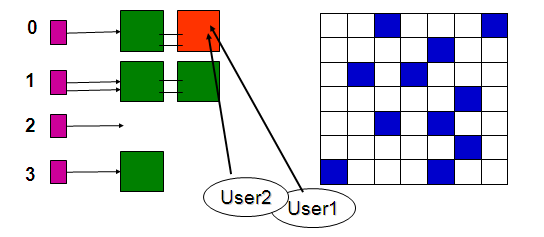
buffer busy waits
The buffer busy waits event occurs
when a session wants to access a data block in the buffer cache that is
currently in use by some other session. The other session is either reading the
same data block into the buffer cache from the datafile, or it is modifying the
one in the buffer cache.
On Oracle 9, the main reasons for buffer busy waits are
- 1) IO read contention (only Oracle 9i and below)
- 2) Insert Block Contention on Tables or Indexes
- 3) Rollback Segment Contention
control file parallel write
The control file parallel write event
occurs when the session waits for the completion of the write requests to all of
the control files. The server process issues these write requests in parallel.
Starting with Oracle 8.0.5, the CKPT process writes the checkpoint position in
the online redo logs to the control files every three seconds. Oracle uses this
information during database recovery operation. Also, when you perform DML
operations using either the NOLOGGING or UNRECOVERABLE option, Oracle records
the unrecoverable SCN in the control files. The Recovery Manager (RMAN) records
backup and recovery information in control files.
db file parallel read
Contrary to what the name suggests, the db
file parallel read event is not related to any parallel operation—neither
parallel DML nor parallel query. This event occurs during the database recovery
operation when database blocks that need changes as a part of recovery are read
in parallel from the datafiles. This event also occurs when a process reads
multiple noncontiguous single blocks from one or more datafiles.
db file parallel write
Contrary to what the name suggests, the db
file parallel write event is not related to any parallel DML operation. This
event belongs to the DBWR process, as it is the only process that writes the
dirty blocks to the datafiles. The blocker is the operating system I/O
subsystem. This can also have an impact on the I/O subsystem in that the writes
may impact read times of sessions reading from the same disks.
db file scattered read
The db file scattered read event is
posted by the session when it issues an I/O request to read multiple data
blocks. The blocks read from the datafiles are scattered into the buffer cache.
These blocks need not remain contiguous in the buffer cache. The event typically
occurs during full table scans or index fast full scans. The initialization
parameter, DB_FILE_MULTIBLOCK_READ_COUNT determines the maximum number of data
blocks to read.
db file sequential read
The db file sequential read wait event
occurs when the process waits for an I/O completion for a sequential read. The
name is a bit misleading, suggesting a multiblock operation, but this is a
single block read operation. The event gets posted when reading from an index,
rollback or undo segments, table access by rowid, rebuilding control files,
dumping datafile headers, or the datafile headers.
db file single write
The db file single write event is
posted by DBWR. It occurs when Oracle is updating datafile headers, typically
during a checkpoint. You may notice this event when your database has an
inordinate number of database files.
direct path read
The direct path read event occurs when
Oracle is reading data blocks directly into the session’s PGA instead of the
buffer cache in the SGA. Direct reads may be performed in synchronous I/O or
asynchronous I/O mode, depending on the hardware platform and the value of the
initialization parameter, DISK_ASYNCH_IO. Direct read I/O is normally used while
accessing the temporary segments that reside on the disks. These operations
include sorts, parallel queries, and hash joins.
direct path write
The direct path write wait event is
just an opposite operation to that of direct path read.
Oracle writes buffers from the session’s PGA to the datafiles. A session can
issue multiple write requests and continue processing. The OS handles the I/O
operation. If the session needs to know if the I/O operation was completed, it
will wait on direct path write event.
enqueue
An enqueue is a shared memory structure used by Oracle to
serialize access to the database resources. The process must acquire the enqueue
lock on the resource to access it. The process will wait on this event if the
request to acquire the enqueue is not successful because some other session is
holding a lock on the resource in an incompatible mode. The processes wait in
queue for their turn to acquire the requested enqueue. A simple example of such
an enqueue wait is a session waiting to update a row when some other session has
updated the row and not yet committed (or rolled back) its transaction and has a
lock on it in an exclusive mode.
free buffer waits
The free buffer waits event occurs
when the session cannot find free buffers in the database buffer cache to read
in data blocks or to build a consistent read (CR) image of a data block. This
could mean either the database buffer cache is too small, or the dirty blocks in
the buffer cache are not getting written to the disk fast enough. The process
will signal DBWR to free up dirty buffers but will wait on this event.
latch free
The latch free wait occurs when the
process waits to acquire a latch that is currently held by other process. Like
enqueue, Oracle uses latches to protect data structures. One process at a time
can either modify or inspect the data structure after acquiring the latch. Other
processes needing access to the data structure must wait till they acquire the
latch. Unlike enqueue, processes requesting latch do not have to wait in a
queue. If the request to acquire a latch fails, the process simply waits for a
short time and requests the latch again. The short wait time is called “spin”.
If the latch is not acquired after one or more spin iterations, the process
sleeps for a short time and tries to acquire the latch again, sleeping for
successively longer periods until the latch is obtained.
library cache pin
The library cache pin wait event is
associated with library cache concurrency. It occurs when the session tries to
pin an object in the library cache to modify or examine it. The session must
acquire a pin to make sure that the object is not updated by other sessions at
the same time. Oracle posts this event when sessions are compiling or parsing
PL/SQL procedures and views.
library cache lock
The library cache lock event is also
associated with library cache concurrency. A session must acquire a library
cache lock on an object handle to prevent other sessions from accessing it at
the same time, or to maintain a dependency for a long time, or to locate an
object in the library cache.
log buffer space
The log buffer space wait occurs when
the session has to wait for space to become available in the log buffer to write
new information. The LGWR process periodically writes to redo log files from the
log buffer and makes those log buffers available for reuse. This wait indicates
that the application is generating redo information faster than LGWR process can
write it to the redo files. Either the log buffer is too small, or redo log
files are on disks with I/O contention.
log file parallel write
The log file parallel write wait
occurs when the session waits for LGWR process to write redo from log buffer to
all the log members of the redo log group. This event is typically posted by
LGWR process. The LGWR process writes to the active log file members in parallel
only if the asynchronous I/O is in use. Otherwise, it writes to each active log
file member sequentially.
log file sequential read
The log file sequential read wait
occurs when the process waits for blocks to be read from the online redo logs
files. The ARCH process encounters this wait while reading from the redo log
files.
log file switch (archiving needed)
The log file switch wait indicates
that the ARCH process is not keeping up with LGWR process writing to redo log
files. When operating the database in archive log mode, the LGWR process cannot
overwrite or switch to the redo log file until the ARCH process has archived it
by copying it to the archived log file destination. A failed write to the
archive log file destination may stop the archiving process. Such an error will
be reported in the alert log file.
log file switch (checkpoint incomplete)
The log file switch wait indicates
that the process is waiting for the log file switch to complete, but the log
file switch is not possible because the checkpoint process for that log file has
not completed. You may see this event when the redo log files are sized too
small.
log file switch completion
This wait event occurs when the process is waiting for log
file switch to complete.
log file sync
When a user session completes a transaction, either by a
commit or a rollback, the session’s redo information must be written to the redo
logs by LGWR process before the session can continue processing. The process
waits on this event while LGWR process completes the I/O to the redo log
file.
SQL*Net message from client
This wait event is posted by the session when it is waiting
for a message from the client to arrive. Generally, this means that the session
is sitting idle. Excessive wait time on this event in batch programs that do not
interact with an end user at a keyboard may indicate some inefficiency in the
application code or in the network layer. However, the database performance is
not degraded by high wait times for this wait event, because this event clearly
indicates that the perceived database performance problem is actually not a
database problem.
SQL*Net message to client
This wait event is posted by the session when it is sending
a message to the client. The client process may be too busy to accept the
delivery of the message, causing the server session to wait, or the network
latency delays may be causing the message delivery to take longer.
Monday, July 23, 2012
Is there any way to avoid buffer busy wait?
- Buffer busy waits occur when an Oracle session needs to access a block in the buffer cache, but cannot because the buffer copy of the data block is locked. This buffer busy wait condition can happen if the block is being read into the buffer by another session, so the waiting session must wait for the block read to complete or another session has the buffer block locked in a mode that is incompatible with the waiting session's request.
- The main way to reduce buffer busy waits is to reduce the total I/O on the system. This can be done by tuning the SQL to access rows with fewer block reads (i.e., by adding indexes). Even if we have a huge db_cache_size, we may still see buffer busy waits, and increasing the buffer size won't help.
- What's the nature of the queries encountering the buffer busy wait? What kind of segment did you identify? Table? Index? If index, what block? root block? first level branch block?
- When I see lots of buffer busy waits, I look at the SQL encountering the wait, see if there are opportunities to reduce concurrency, and/or tune the SQL.
- Cache the table or keep the table in the KEEP POOL. When multiple sessions are requesting the blocks that reside in the disk, it takes too much time for a session to read it into the buffer cache. Other session(s) that need the same block will register 'buffer busy wait'. If the block is already in buffer cache, however, this possibility is eliminated. Another alternative is to increase the buffer cache size. A larger buffer cache means less I/O from disk. This reduces situations where one session is reading a block from the disk subsystem and other sessions are waiting for the block.
- Look for ways to reduce the number of low cardinality indexes, i.e. an index with a low number of unique values that could result in excessive block reads. This can especially be problematic when concurrent DML operates on table with low cardinality indexes and cause contention on a few index blocks.
- The most common remedies for high buffer busy waits include database writer (DBWR) contention tuning, adding freelists to a table and index, implementing Automatic Segment Storage Management (ASSM, a.k.a bitmap freelists), and, of course, and adding a missing index to reduce buffer touches.
- Tune inefficient queries that read too many blocks into the buffer cache. These queries could flush out blocks that may be useful for other sessions in the buffer cache. By tuning queries, the number of blocks that need to be read into the cache is minimized, reducing aging out of the existing "good" blocks in the cache.
- The v$session_wait performance view, can give some insight into what is being waited for and why the wait is occurring.
- When sessions insert/delete rows into/from a block, the block must be taken out of the freelist if the PCTFREE threshold reached. When sessions delete rows from a block, the block will be put back in the freelist if PCTUSED threshold is reached. If there are a lot of blocks coming out of the freelist or going into it, all those sessions have to make that update in the freelist map in the segment header. A solution to this problem is to create multiple freelists. This will allow different insert streams to use different freelists and thus update different freelist maps. This reduces contention on the segment header block. You should also look into optimizing the PCTUSED/PCTFREE parameters so that the blocks don't go in and out of the freelists frequently. Another solution is to use ASSM which avoids the use of freelists all together.
- If extents are too small, Oracle must constantly allocate new extents causing contention in the extent map
Simple way to simplify summary management in large databases
Oracle's materialized views are a way to simplify summary management in large
databases. The beauty of Oracle's materialized view facility is that once the
views are created, they are automatically updated by the database whenever there
are changes in the underlying base tables on which the view is defined. The
materialized views are completely transparent to the users. If users write
queries using the underlying table, Oracle will automatically rewrite those
queries to use the materialized views. The Oracle Optimizer will automatically
decide to use the materialized view rather than the underlying tables and views
if it would be more efficient to do so. Complex joins involve a lot of overhead
and the use of the materialized views will avoid incurring this cost each time
you need to perform such joins. Because the materialized views already have the
summary information precomputed in them, your queries will run much faster.
You can also partition materialized views and create indexes on
them if necessary. A major problem with the aggregate or summary tables is their
maintenance, which involves keeping the tables in accord with the base tables
that are being constantly modified. If you aren't sure about which materialized
views to create, you can take advantage of Oracle's Summary Advisor, which can
make specific recommendations based on its use of the DBMS_OLAP package.
Saturday, July 21, 2012
When to Partition your data
There are two main reasons to use partitioning in a large database environment. These reasons are related to management and performance improvement. Partitioning offers:
- Management at the individual partition level for data loads, indexcreation and rebuilding, and backup/recovery. This can result in less down time because only individual partitions being actively managed are unavailable.
- Increased query performance by selecting only from the relevant partitions. This weeding out process eliminates the partitions that do not contain the data needed by the query through a technique called
partition pruning. - When a table reaches a “large” size. Large is defined relative to your environment. Tables greater than 2GB should always be considered for partitioning.
- When the archiving of data is on a schedule and is repetitive. For instance, data warehouses usually hold data for a specific amount of time (rolling window). Old data is then rolled off to be archived.
Oracle 9.2.0.4 real installation guide for RHEL-5 64-BIT
1. Make sure Java libraries are up to date.. (sysad side..)
2. Do not start installation from the 9204 base installation- Oracle Universal Installer has problem
2.1 Install first the OUI "only" from the 9206 patchset (p3948480_9206_Linux-x86-64.zip)
using the Oracle_Home youve just decided
2.2 In ../Disk1/install/oraparam.ini edit the Linux value under [Certified Versions]
Linux=redhat-2.1AS,redhat-2.1,redhat-3,redhat-4,redhat-5,UnitedLinux-1.0,SuSE-9,SuSE-
* value must include redhat-5 inorder to suppress the error message for OS version incompat.
2.3 After completion of OUI install, edit again ../product/9204/oui/oraparam.ini as instructed
in step 2.2
2.4 Now install the 9204 base using the OUI from 9206. Run ../product/9204/oui/runInstaller BUT
this time, select the "products.jar" from 9204 base installation set.
(ex: /u01/app/oracle/Disk1/stage/products.jar)
2.5 From here u should be able to install the SOFTWARE ONLY option. DO NOT create a database yet.
3. Patch the 9204 base with the 9207 patchset (p4163445_92070_Linux-x86-64.zip)
3.1 After decompressing contents, repeat step 2.2 again to suppress OS version incompat.
3.2 Now proceed with the patch application
4. You can now create a database using the "dbca" utility.
2. Do not start installation from the 9204 base installation- Oracle Universal Installer has problem
2.1 Install first the OUI "only" from the 9206 patchset (p3948480_9206_Linux-x86-64.zip)
using the Oracle_Home youve just decided
2.2 In ../Disk1/install/oraparam.ini edit the Linux value under [Certified Versions]
Linux=redhat-2.1AS,redhat-2.1,redhat-3,redhat-4,redhat-5,UnitedLinux-1.0,SuSE-9,SuSE-
* value must include redhat-5 inorder to suppress the error message for OS version incompat.
2.3 After completion of OUI install, edit again ../product/9204/oui/oraparam.ini as instructed
in step 2.2
2.4 Now install the 9204 base using the OUI from 9206. Run ../product/9204/oui/runInstaller BUT
this time, select the "products.jar" from 9204 base installation set.
(ex: /u01/app/oracle/Disk1/stage/products.jar)
2.5 From here u should be able to install the SOFTWARE ONLY option. DO NOT create a database yet.
3. Patch the 9204 base with the 9207 patchset (p4163445_92070_Linux-x86-64.zip)
3.1 After decompressing contents, repeat step 2.2 again to suppress OS version incompat.
3.2 Now proceed with the patch application
4. You can now create a database using the "dbca" utility.
Wednesday, July 18, 2012
Why you should use Automatic segment space management (ASSM)
Automatic segment space management (ASSM)
is a simpler and more efficient way of managing space
within a segment. It completely eliminates any need to
specify and tune the pctused, freelists, and
freelist groups storage parameters for schema
objects created in the tablespace. If any of these
attributes are specified, they are ignored.
ASSM is not for every database, especially those with super-high DML
rates:
Varying row sizes:
ASSM is better than a static pctused. The bitmaps make
ASSM tablespaces better at handling rows with wide variations in row
length.
Reducing buffer busy
waits: ASSM will remove buffer busy
waits better than using multiple freelists. When a table has
multiple freelists, all purges must be parallelized to reload
the freelists evenly, and ASSM has no such limitation.
Great for Real
Application Clusters: The bitmap freelists remove the need to
define multiple freelists groups for RAC and provide overall
improved freelist management over traditional freelists.
How to identify buffer cache objects ?
SELECT o.owner owner,
o.object_name object_name,
o.subobject_name subobject_name,
o.object_type object_type,
COUNT (DISTINCT file# || block#) num_blocks
FROM dba_objects o, v$bh bh
WHERE o.data_object_id = bh.objd
AND o.owner NOT IN ('SYS', 'SYSTEM')
AND bh.status != 'free'
GROUP BY o.owner,
o.object_name,
o.subobject_name,
o.object_type
ORDER BY COUNT (DISTINCT file# || block#) DESC;
o.object_name object_name,
o.subobject_name subobject_name,
o.object_type object_type,
COUNT (DISTINCT file# || block#) num_blocks
FROM dba_objects o, v$bh bh
WHERE o.data_object_id = bh.objd
AND o.owner NOT IN ('SYS', 'SYSTEM')
AND bh.status != 'free'
GROUP BY o.owner,
o.object_name,
o.subobject_name,
o.object_type
ORDER BY COUNT (DISTINCT file# || block#) DESC;
Tuesday, July 17, 2012
Identifying tables and indexes belonging to the same tablespace
SELECT tab.table_name,
ind.index_name,
ind.tablespace_name ind_tbs,
tab.tablespace_name tab_tbs
FROM dba_tables tab, dba_indexes ind
WHERE TAB.TABLE_NAME = IND.TABLE_NAME
AND ind.tablespace_name = tab.tablespace_name
AND tab.owner NOT IN ('SYS', 'SYSTEM')
AND ind.owner NOT IN ('SYS', 'SYSTEM')
AND ind.tablespace_name != 'SYSTEM'
AND tab.tablespace_name != 'SYSTEM'
ind.index_name,
ind.tablespace_name ind_tbs,
tab.tablespace_name tab_tbs
FROM dba_tables tab, dba_indexes ind
WHERE TAB.TABLE_NAME = IND.TABLE_NAME
AND ind.tablespace_name = tab.tablespace_name
AND tab.owner NOT IN ('SYS', 'SYSTEM')
AND ind.owner NOT IN ('SYS', 'SYSTEM')
AND ind.tablespace_name != 'SYSTEM'
AND tab.tablespace_name != 'SYSTEM'
Saturday, July 14, 2012
Best way to specify columns order in an Oracle concatened index
If I have a table called Test contains 5 columns a, b, c, d and e.
1. What is the deference between index_1, and index_2 if they are defined as:-
Index_1.
Create index_1 on test (a, b);
Index_2.
Create index_2 on test (b, a).
Is the order in columns making difference? What is the deference and how it effect.
The order of the columns can make a difference. index_1 would be most useful if you ask queries such as: select * from t where a = :a and b = :b; select * from t where a = :a;Index_2 would be most useful if you ask queries such as: select * from t where a = :a and b = :b; select * from t where b = :b; (in 9i, there is a new "index skip scan" -- search for that there to read about that. It makes the index (a,b) OR (b,a) useful in both of the above cases sometimes!) So, the order of columns in your index depends on HOW YOUR QUERIES are written. You want to be able to use the index for as many queries as you can (so as to cut down on the over all number of indexes you have) -- that will drive the order of the columns. Nothing else (selectivity of a or b does not count at all)An Index Skip Scan can only actually be used and considered by the CBO in very specific scenarios and is often an indicator there’s either a missing index or an exisiting index has the columns in the wrong order.If the leading column of an index is missing, it basically means the values in subsequently referenced columns in the index can potentially appear anywhere within the index structure as the index entries are sorted primarily on the leading indexed column. So if we have column A with 100,000 distinct values and column B with 100,000 distinct values and an index based on (A,B), all index entries are sorted primarily on column A and within a specific value of column A, sorted by column B. Therefore if we attempt a search on just Column B = 42, these values could potentially appear anywhere within the index structure and so the index can not generally be effectively used.However, what if the leading column actually contained very few distinct values ? Yes, the subsequent column(s) values could appear anywhere within the index structure BUT if these subsequent columns have relatively high cardinality, once we’ve referenced the required index entries for a specific occurrence of a leading column value, we can ignore all subsequent index row entries with the same leading column value. If the leading column has few distinct values, this means we can potentially “skip” several/many leaf blocks until the leading column value changes again, where we can again ”probe” the index looking for the subsequent indexed column values of interest.So if we have a leading column with few distinct values, we may be able to use the index “relatively” efficiently by probing the index as many times as we have distinct leading column values.
Oracle statistics : to estimate or compute ?
Both computed and estimated statistics are used by the Oracle optimizer to
choose the execution plan for SQL statements that access analyzed objects.
These statistics may also be useful to application developers who write such statements.
COMPUTE STATISTICS
COMPUTE STATISTICSinstructs Oracle to compute exact statistics about the analyzed object and store them in the data dictionary. When computing statistics, an entire object is scanned to gather data about the object. This data is used by Oracle to compute exact statistics about the object. Slight variances throughout the object are accounted for in these computed statistics. Because an entire object is scanned to gather information for computed statistics, the larger the size of an object, the more work that is required to gather the necessary information.
To perform an exact computation, Oracle requires enough space to perform a scan and sort of the table. If there is not enough space in memory, then temporary space may be required. For estimations, Oracle requires enough space to perform a scan and sort of only the rows in the requested sample of the table. For indexes, computation does not take up as much time or space, so it is best to perform a full computation.
Some statistics are always computed exactly, such as the number of data blocks currently containing data in a table or the depth of an index from its root block to its leaf blocks.
Use estimation for tables and clusters rather than computation, unless you need exact values. Because estimation rarely sorts, it is often much faster than computation, especially for large tables.
ESTIMATE STATISTICS
ESTIMATE STATISTICSinstructs Oracle to estimate statistics about the analyzed object and stores them in the data dictionary. When estimating statistics, Oracle gathers representative information from portions of an object. This subset of information provides reasonable, estimated statistics about the object. The accuracy of estimated statistics depends upon how representative the sampling used by Oracle is. Only parts of an object are scanned to gather information for estimated statistics, so an object can be analyzed quickly. You can optionally specify the number or percentage of rows that Oracle should use in making the estimate.
To estimate statistics, Oracle selects a random sample of data. You can specify the sampling percentage and whether sampling should be based on rows or blocks.
- Row sampling reads rows without regard to their physical placement on disk. This provides the most random data for estimates, but it can result in reading more data than necessary. For example, in the worst case a row sample might select one row from each block, requiring a full scan of the table or index.
- Block sampling reads a random sample of blocks and uses all of the rows in those blocks for estimates. This reduces the amount of I/O activity for a given sample size, but it can reduce the randomness of the sample if rows are not randomly distributed on disk. Block sampling is not available for index statistics.
- The default estimate of the analyze command reads the first approx 1064 rows of the table so the results often leave a lot to be desired.
- The general consensus is that the default value of 1064 is not sufficient for accurate statistics when dealing with tables of any size. Many claims have shown that estimating statistics on 30 percent produces very accurate results. I personally have been running estimate 35 percent. This seems to produce very accurate numbers. It also saves a lot of time over full scans.
- Note that if an estimate does 50% or more of a table Oracle converts the estimate to a full compute statistics.
Friday, July 13, 2012
how to determine the optimal column order for a composite index
What is the secret for
creating a composite index with the columns in the proper sequence?
- In general, when using a multi-column index, you want to put the most restrictive column value first (the column with the highest unique values) because this will trim-down the result set.
- Because Oracle can only access one index, your job is to
examine your historical SQL workload and build a single
composite index that satisfies the majority of the SQL queries.
- The Oracle optimizer may try to make single column
indexes behave as-if they were a single composite index.
Prior to 10g, this could be done with the "and_equal" hint.
- Beware that indexes have overhead
- You can run scripts to monitor the invocation count for each column in a multiple column composite index
Assign effectivly tables to Oracle buffer pools to maximize performance
Any segments whose blocks tend to be
accessed with less frequency should be assigned to the recycle pool so
that it does not flush the other segments, either in the default cache or
the keep pool.
Segments that contain frequently accessed blocks should be assigned to the keep buffer pool so that the blocks of those segments will not be inadvertently removed, thus impacting performance.
the keep buffer pool is used to retain objects in memory that are likely to be reused. Keeping these objects in memory reduces physical I/O operations. For optimal performance you should make sure that you tune your SQL to reduce logical I/O operations as well as physical operations.
Segments that contain frequently accessed blocks should be assigned to the keep buffer pool so that the blocks of those segments will not be inadvertently removed, thus impacting performance.
the keep buffer pool is used to retain objects in memory that are likely to be reused. Keeping these objects in memory reduces physical I/O operations. For optimal performance you should make sure that you tune your SQL to reduce logical I/O operations as well as physical operations.
Tuesday, July 10, 2012
When Not to Use Indexes in Oracle
There are some circumstances where indexes can be detrimental to performance and
sometimes those indexes should not exist. The Optimizer will occasionally ignore
indexes and consider reading the entire table a faster option.
- A table with a small number of columns may not benefit from an index if a large percentage of its rows are always retrieved from it.
- NULL values are generally not included in indexes. Do not index columns containing many NULL values unless there is a specific use for it such as filtering the column as NOT NULL, thus only scanning the index and the rows without NULL values.
- Indexes should usually be created on a small percentage of the columns in a table. Large composite indexes may be relatively large compared with the table. The relative size between index and table is important. The larger the ratio of index to table physical size then the less helpful the index will be in terms of decreasing physical space to be read. Also many columns not in the index may contain NULL values. It may be faster to read the entire table. Why create indexes?
- Small static data tables may be so small that the Optimizer will simply read those tables as a full table scan and ignore indexes altogether. In some cases the Optimizer may use an index on a small table where it should not since a full table scan would be faster. An exception to this rule will be in mutable joins where unique index hits are often used, even on small tables. If full table scans are faster than index reads in those mutable joins you might want to remove indexes from the small tables altogether or override with hints. Examine your small static data tables. Do they really need indexing ?
Monday, July 9, 2012
ORA-01555 causes and suggestions to avoid it
Here are the causesof this error
- The undo segments are too small
- The application fetches across commits (a design flaw)
- Delayed block cleanout
- Adjust the undo_retention parameter (for 9i and higher releases of Oracle
- Increase the size of the UNDO tablespace
- Increase the size of the undo segments [if using manual UNDO management]
Some factors that can prevent an index from being used in Oracle
The presence of an index on a column does not guarantee it will be used.
- The optimizer decides it would be more efficient not to use the index. If your query is returning the majority of the data in a table, then a full table scan is probably going to be the most efficient way to access the table.
- You perform a function on the indexed column i.e. WHERE UPPER(name) = 'JONES'. The solution to this is to use a Function-Based Index.
- You perform mathematical operations on the indexed column i.e. WHERE salary + 1 = 10001
- You concatenate a column i.e. WHERE firstname || ' ' || lastname = 'JOHN JONES'
- You do not include the first column of a concatenated index in the WHERE clause of your statement. For the index to be used in a partial match, the first column (leading-edge) must be used. Index Skip Scanning in Oracle 9i and above allow indexes to be used even when the leading edge is not referenced.
- The use of 'OR' statements confuses the Cost Based Optimizer (CBO). It will rarely choose to use an index on column referenced using an OR statement. It will even ignore optimizer hints in this situation. The only way of guaranteeing the use of indexes in these situations is to use an INDEX hint.
Thursday, July 5, 2012
How to get paging space informations on IBM AIX
To list the characteristics of all paging spaces, enter: lsps -a
This displays the characteristics for all paging spaces and provides a listing similar to the following listing:
Page Space Physical Volume Volume Group Size %Used Active Auto Type
hd6 hdisk0 rootvg 512MB 1 yes yes lv
This displays the characteristics for all paging spaces and provides a listing similar to the following listing:
Page Space Physical Volume Volume Group Size %Used Active Auto Type
hd6 hdisk0 rootvg 512MB 1 yes yes lv
Wednesday, July 4, 2012
Avoid double caching to improve disk I/O performance in Oracle
If Oracle data are stored in a Filesystem a Concurrent IO mount option can improve performance ...
- Data is transfered directly from the disk to the application buffer, bypassing the file buffer cache hence avoiding double caching (filesystem cache + Oracle SGA)
- Emulates a raw-device implementation
- Give a faster access to the backend disk and reduce the CPU utilization
- Disable the inode-lock to allow several threads to read and write the same file
Subscribe to:
Posts (Atom)